PelAtlas
Building a scalable, ML-assisted workflow for marine mammal photo-ID and capture–recapture studies, combining retrieval-based re-identification with human verification and active learning.
Context
Capture–recapture studies rely on consistent individual identification across repeated encounters. In marine mammal research, this is often done via photo-identification (photo-ID), using stable visual cues such as dorsal fin shape, nicks, scars, and pigmentation patterns.
In practice, the limiting factor is rarely the downstream ecological modeling — it’s the manual work needed to turn raw survey imagery into a traceable catalog: filtering images for animal presence, isolating identity-relevant regions, matching against a growing set of known individuals, and keeping the catalog consistent over time.
PelAtlas is motivated by a long-term, real-world dataset context: a large archive of boat-survey imagery accumulated over ~20 years, with heterogeneous quality and incomplete metadata, where only a subset of images is suitable for identification.
Project focus
PelAtlas aims to build a maintainable pipeline that reduces expert workload while preserving scientific traceability.
The project is structured as a stage-wise workflow aligned with the practical bottlenecks of photo-ID:
- Stage 1: Presence filtering (high recall): separate likely relevant images from background.
- Stage 2: Region proposals: extract typed identity evidence (fin-first; multi-region later).
- Stage 3: Embeddings + within-sighting grouping: aggregate evidence across multiple frames to stabilize matching.
- Stage 4: Retrieval + open-set handling + expert verification: propose top-k candidates with an explicit “unknown” option, then log human decisions as the scientific record and as training signal.
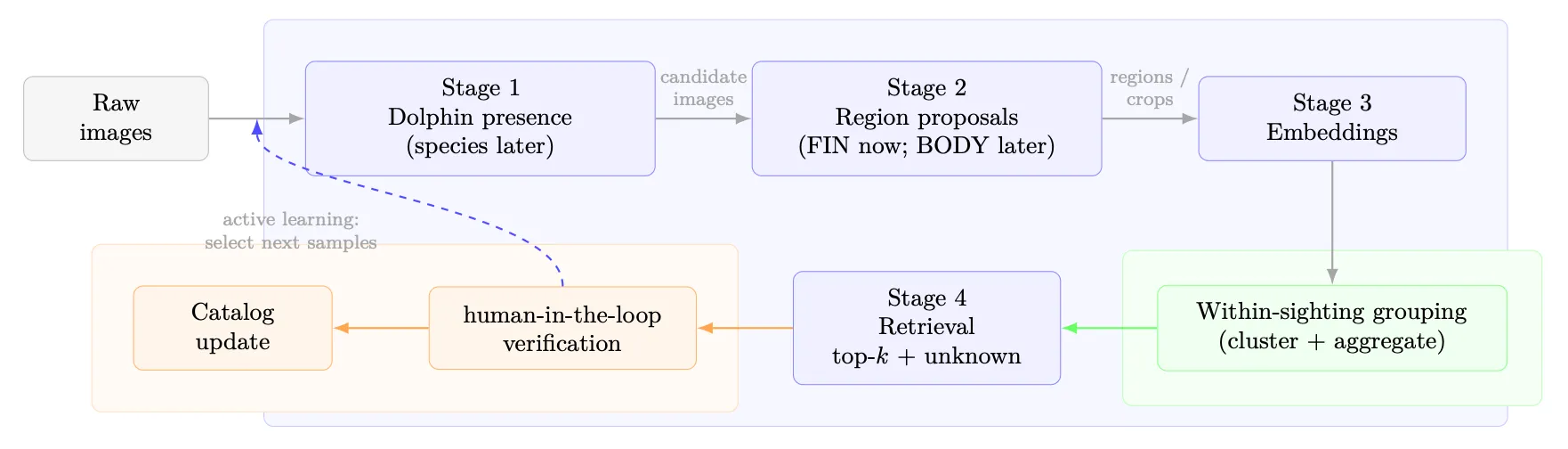
A central design principle is decision support rather than full automation: the system proposes evidence and candidates; experts confirm, reject, or create a new identity entry.
Collaboration
PelAtlas is developed in a small, tightly coupled collaboration:
- Oihana Olhasque — marine mammal photo-ID workflow context, field and expert perspective, requirements shaping
- Jan Meischner — workflow and system design, ML pipeline architecture, evaluation design, implementation coordination
The project is motivated by an NGO field-work context and is designed around real operational constraints rather than benchmark-style assumptions.
My role
I lead the technical side: defining the stage-wise pipeline, designing the data model and provenance strategy, and building the ML-assisted workflows that connect ingestion, model inference, review, and catalog updates.
A key part of my role is ensuring that the system remains scientifically robust as it scales: defining clear baselines, structuring evaluation across stages, and making sure that human decisions remain traceable and reproducible over time.
Implementation
Implementation is approached as a minimal, maintainable system that supports both historical backfill and continuous ingestion:
- survey and sighting as first-class organizational units, enabling within-sighting grouping and context-aware processing
- asynchronous processing for compute-heavy steps (ingest, inference, embedding, indexing)
- traceable decision logging: for each verification, store the evidence shown, the model version, and the final human outcome
- open-set behavior as a hard requirement to avoid systematic incorrect merges in the catalog
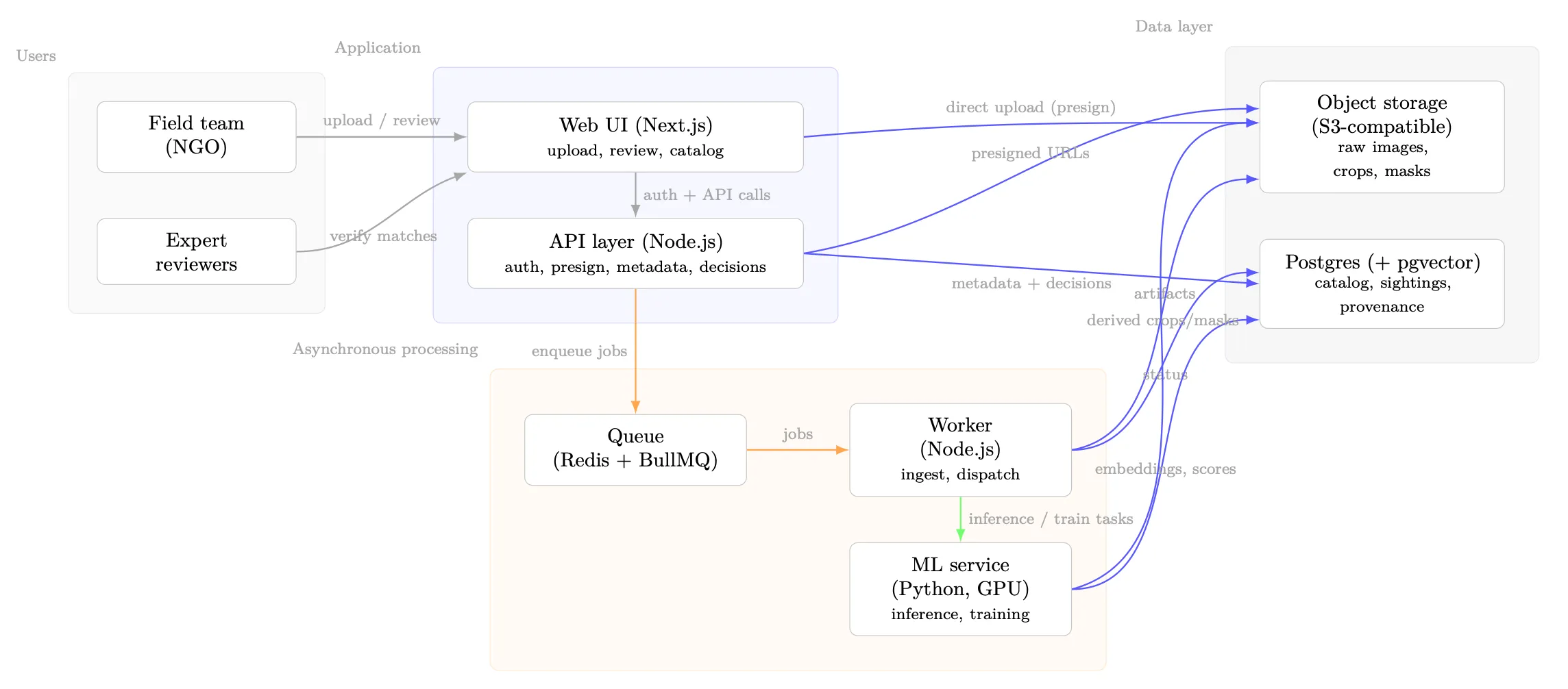
Stack
Expected outcomes
- A reproducible, continuously ingestible workflow from raw survey images to verified catalog updates
- Baselines and ablations for each stage, plus end-to-end workflow evaluation (expert effort and catalog quality)
- A fin-first re-identification setup for bottlenose dolphins (retrieval-based, open-set, auditable)
- A path to multi-region evidence (Risso-ready) without changing the overall retrieval framing
- A structured foundation for scaling label efficiency via active learning (and, later, carefully scoped non-expert tasks)
Learnings
- For long-term datasets, “data and workflow engineering” is not a side task — it often determines what modeling is feasible at all.
- Open-set handling is not optional in photo-ID: forced matches can silently corrupt capture histories.
- Within-sighting aggregation is not just an optimization; it aligns the system with how experts reason and reduces redundant decisions.
Related Writing
A week of exchange, alignment, and first architectural decisions for PelAtlas under the EU-CONEXUS DELPHI project.